
Les mois passent, jusqu’au jour du 10 juin 2020, où Spark 3.0.0 finit par sortir (Preview release) ! Plus de 3400 tickets Jira ont été résolues par 440 contributeurs. On peut donc s’attendre à une évolution prometteuse, surtout pour fêter les 10 ans de Spark en tant que projet open-source !
Les grandes nouveautés de Spark 3.0
- Spark 3.0 tourne sur Python 3 et Scala passe à la version 2.12. De plus, Java JDK 11 est entièrement supporté et de fait, Python 2 est fortement déprécié.
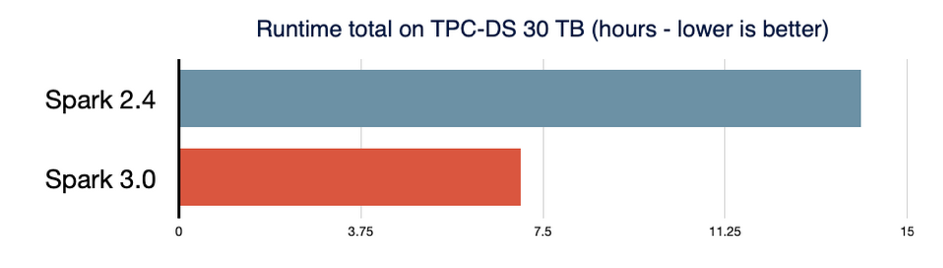
- 2 fois plus performant que Spark 2.4 sur le test TPC-DS grâce aux divers optimisations tel que l’adaptive query execution ou le dynamic partition pruning.
- ANSI SQL Compliance offre une meilleure gestion des overflows dans les opérations arithmétiques et un contrôle plus fort sur la conversion des types de données entre autres.
- Nombreuses améliorations dans l’utilisation des pandas API.
- Meilleure gestion des erreurs Python, simplification des exceptions PySpark (Yes !).
- Nouvelle interface utilisateur pour visualiser les streams structurées.
Spark SQL : le focus sur cette évolution
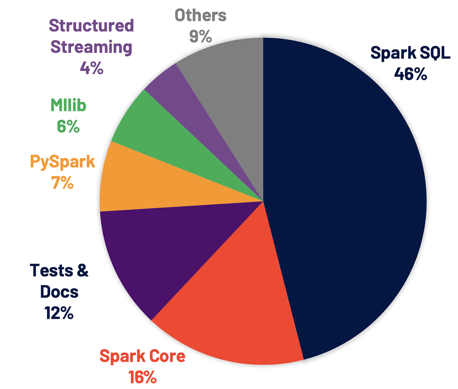
Si plus de 3400 patches ont été appliqués, environ 46% de ces patchs concernent Spark SQL.
Ce qui finalement n’est pas très étonnant puisqu’au fil des années Spark est devenu une technologie qui s’étend sur plusieurs domaines, développant de nouvelles capacités notamment autour du streaming. Python et SQL constituent cependant les uses cases les plus répandus pour Spark, il reste la référence en terme de data processing, data science, machine learning et data analytics. Spark 3.0 continue sur cette tendance en améliorant considérablement le support pour SQL et Python.
Amélioration du Spark SQL Engine
Spark SQL est le moteur qui soutient la plupart des applications Spark. Lorsque l’on manipule des DataFrames ou des DataSet, c’est bien grâce au Spark SQL Engine. Comme déjà mentionné plus haut, 46% des tickets JIRA concernent Spark SQL, améliorant ainsi les performances de cette dernière ainsi que la compatibilité avec ANSI.
De nombreuses optimisations ont été implémentées pour atteindre un tel résultat. Nous allons donc évoquer quatre fonctionnalités de Spark SQL Engine.
Adaptive Query Execution (AQE)
Le nouveau framework AQE améliore les performances en générant un meilleur plan d’exécution au moment du runtime. Dû à la distinction faite entre le stockage et le traitement par Spark, l’arrivée des données peut être imprévisible. De ce fait, la capacité d’adaptation devient critique pour Spark, cette version introduit trois nouvelles optimisations majeures : Dynamic coalescing shuffle, Dynamic switching join et Dynamic optimizing skew joins. Pour plus de détails sur ces optimisations, ainsi que des résultats de ces améliorations, vous pouvez consulter cet article de Databricks.
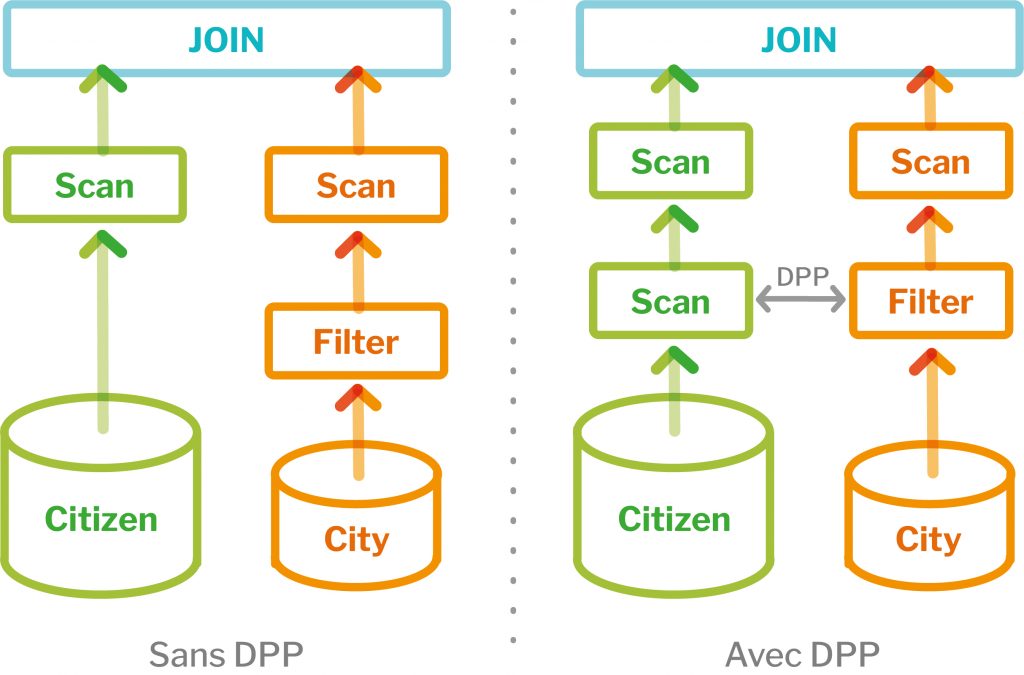
Dynamic Partition Pruning (DPP)
DPP est une autre fonctionnalité majeure dans l’amélioration des performances pour les traitements BI.
En prenant en exemple la requête suivante :

Avant Spark 3.0, un filtre était appliqué sur la table city puis le join des deux tables était effectué. Avec Spark 3.0, le filtre est appliqué sur city puis envoyé dynamiquement aux partitions de la table citizen et enfin le join est appliqué.
ANSI SQL compliance
Spark 3.0 inclut également la compatibilité avec la conformité ANSI SQL, elle est essentielle pour la migration des workloads effectués sur d’autres moteurs SQL à Spark SQL. Pour améliorer la conformité, cette version de Spark change pour le calendrier Proleptic Gregorian. Il permet également aux utilisateurs d’interdire l’utilisation des mots-clés réservés d’ANSI SQL comme identificateurs.
En outre, il y a une meilleure gestion des overflows dans les opérations arithmétiques et un contrôle plus fort sur la conversion des types de données lors d’une insertion de données dans une table avec un schéma prédéfini. Cette évolution permet d’améliorer la qualité de la donnée.
Join hints
Il est possible d’influencer le choix des algorithmes de jointure lors de la création du plan d’exécution du job Spark. Cette version ajoute ces nouveaux hints SHUFFLE_MERGE, SHUFFLE_HASH and SHUFFLE_REPLICATE_NL.
Découvrez avec quel outil nous valorisons les flux de données
L’amélioration de PySpark et l’arrivée des Koalas
Python est la langue la plus utilisée sur Spark. En conséquence, Spark 3.0 a été amélioré sur son intégration. Il faut savoir que beaucoup de développeurs Python utilisent l’API Pandas pour la structuration des données et leur analyse, mais les traitements étaient limités sur un seul nœud, donc pas de parallélisation possible.
C’est donc pour répondre à cette limitation que Koalas a été développé. Il s’agit d’une implémentation de l’API Pandas sur Spark pour permettre aux data scientists d’être plus productifs quand ils travaillent sur des environnements Big Data distribués.
Actuellement, Koalas couvre quasiment 80% de l’API Pandas. Il évolue très rapidement et a déjà atteint 850 000 téléchargements.
En parallèle, l’API PySpark gagne également en popularité. Spark 3.0 y apporte quelques améliorations, notamment une meilleure gestion des erreurs. En effet la gestion d’erreurs PySpark n’est pas toujours user-friendly pour les utilisateurs de Python. Celles-ci ont été simplifiées, en cachant par exemple les dispensables stack traces de la JVM.

Streaming et GPU
L’une des promesses faites avec Spark 3.0 est la capacité d’utiliser des GPU (AMD, Nvidia) dans le cadre du deep learning. C’est pour cela que le projet Hydrogen a été mis en place.
Celui-ci permet d’unifier le deep learning et le data processing sur Spark. Les GPUs et autres accélérateurs sont utilisés pour accélérer les traitements deep learning. Pour que Spark puisse prendre avantage de ces accélérateurs, il faut au préalable que le cluster manager soit connecté à ces accélérateurs (YARN, Kubenertes etc.). Les utilisateurs pourront créer des configurations spécifiques avec l’aide d’un discovery script (en vous rendant sur cette page, vous pourrez choisir entre les différents clusters managers supportés pour avoir une documentation plus détaillée).
Le streaming structuré était introduit depuis Spark 2.0. Avec Spark 3.0, une nouvelle interface web, dédiée au streaming a été créée pour l’inspection des jobs Spark. Cette interface offre deux parties de statistiques : les informations agrégées des requêtes des jobs streaming terminées et des statistiques détaillées sur les requêtes streaming.
D’autres mises à jour incluses dans Spark 3.0
Bien que l’article de cette mise à jour se soit nettement focalisé sur Spark SQL, Spark 3.0 apporte bien plus comme SparkGraph, qui reprend le fonctionnement de Neo4j et son langage Cypher ou encore l’intégration de Spark avec Kubenertes. Elles sont couvertes en détail sur le site de Spark.

Avec toutes ces nouveautés et dix ans après la première sortie, Spark continue d’être une référence dans le data processing tout en s’étendant sur les autres domaines tel que le deep learning et la BI.
Si vous voulez tester par vous-même Spark 3.0, vous pouvez le télécharger sur le site officiel et choisir la release 3.0.0 (Jun 18 2020).
A lire dans la même thématique : Architectures Big Data “Lambda, Kappa et Datalake”





