
A l’ère du tout automatique, penchons-nous sur une méthode qui fait ses preuves chez nos clients : incorporer Ansible dans les déploiements Big Data.
Pour clore cette série d’articles, nous allons voir comment gérer automatiquement les structures des tables Impala et Hive avec Ansible.
Episode 3 – Impala / Hive
Dans certains projets clients on retrouve les systèmes de base de données distribuées Impala et Hive. Comme pour tout Système de Gestion de Base de Données (SGBD), la montée de version des tables à travers les environnements est importante !
Pour réussir ce cela, nous utilisons une combinaison de module Ansible décrite ci-dessous.
Kerberos
Tout d’abord, la gestion des tickets Kerberos doit être faite en amont de ce type de processus. Nous avions d’ailleurs déjà traité ce sujet dans un article précédent sur HDFS.
Stockage des fichiers des tables
Pour commencer, il est nécessaire de récupérer les scripts des tables du datalake. Ceux-ci sont versionnés dans l’infrastructure cliente.
Nous préconisons la solution [une table = un script] pour garder de la souplesse sur l’édition des fichiers. Il faut par conséquent accepter que le traitement puisse être lent en raison de l’exécution unitaire des scripts.
Pour récupérer les fichiers, il existe deux méthodes que nous sommes amenés à utiliser :
- Utilisation d’un module de type curl sur une interface web
- Checkout d’un repository Git/Svn en local
Format des fichiers
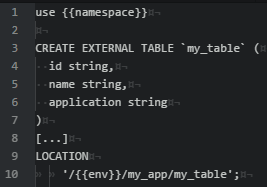
Lorsqu’on écrit des fichiers HQL pour Impala ou Hive, dans un cadre de déploiement de grande envergure, nous altérons légèrement la syntaxe en plaçant des variables Jinja2. Ainsi nous pouvons utiliser le module Ansible « template » et bénéficier des variables de contexte lors de l’exécution du playbook de déploiement. Cela nous permet notamment :
- De s’affranchir de l’environnement sur lequel nous exécutons la requête
- De rendre dynamique le namespace visé
- De rendre dynamique le chemin des tables externes si nécessaire
Exécution des scripts
Après avoir poussé les scripts sur un serveur doté de HDFS, nous appelons le module Ansible « shell » pour exécuter Beeline comme suit :

Nous choisissons d’exécuter le script via Hive. La puissance d’Ansible pour la contextualisation, nous permet d’avoir une variable HIVE définie pour chaque environnement afin de ne pas avoir à gérer la connexion et l’authentification dans ce playbook.
Nous utilisons également une autre variable IMPALA qui se comporte de la même manière, pour exécuter d’autres playbook sur Impala.
Gestion des versions
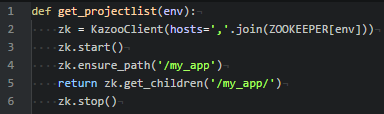
L’objectif à termes étant de pouvoir enregistrer dans une table Impala, les versions de tables déployées.
La plus grande problématique à l’heure actuelle reste la gestion des versions. Pour le moment nous renseignons la version de tables déployées dans Zookeeper grâce au module Ansible « znode ». Pour ensuite la récupérer via une application web faite maison, avec Flask et la librairie python Kazoo.
Aller plus loin…
Nous travaillons actuellement sur un module Ansible Impala afin de transformer ce que l’on vient de voir et rendre le travail le plus idempotent possible.
Si vous êtes intéressé par ces problématiques, n’hésitez pas à nous contacter, sur notre site ou via twitter sur notre page @cyresgroupe.
___
Make data yours !
___




