
Apache Druid est une base de données analytique axé temps réel offrant la possibilité de persister des quantités de données immenses et d’en extraire de l’information à une vitesse hallucinante, le tout couvrant de nombreux use cases. L’architecture Druid aurait donc tout pour plaire.
La dernière version stable de Druid est la 0.20.0 ; il est utilisé en production par de grands groupes tel que AirBnB, eBay, Cisco ou encore Netflix.
La technologie reste assez récente puisque Druid naît en 2011 en tant que produit de Metamarkets. Il devient open-source en 2012. Druid est à ce jour sous licence Apache depuis Février 2015.
L’architecture Druid est de plus en plus utilisée car elle tient ses promesses en termes de performance. Elle est près de 100 fois plus rapide que les solutions de bases de données plus connus comme Hive ou Presto durant le Star Schema Benchmark.
Devant de telles promesses, plus le fait que Druid est intégré dans la Cloudera Data Platform (CDP), le but de cet article est d’expliquer le fonctionnement de certains mécanismes, pour vous donner un tour d’horizon des possibilités.
L’architecture d’Apache Druid
Le premier point à évoquer est l’architecture de Druid en elle même. L’écosystème est divisé en plusieurs parties, chaque partie peut être déployée dans des hôtes différents, permettant à Druid de fonctionner dans un environnement distribué.
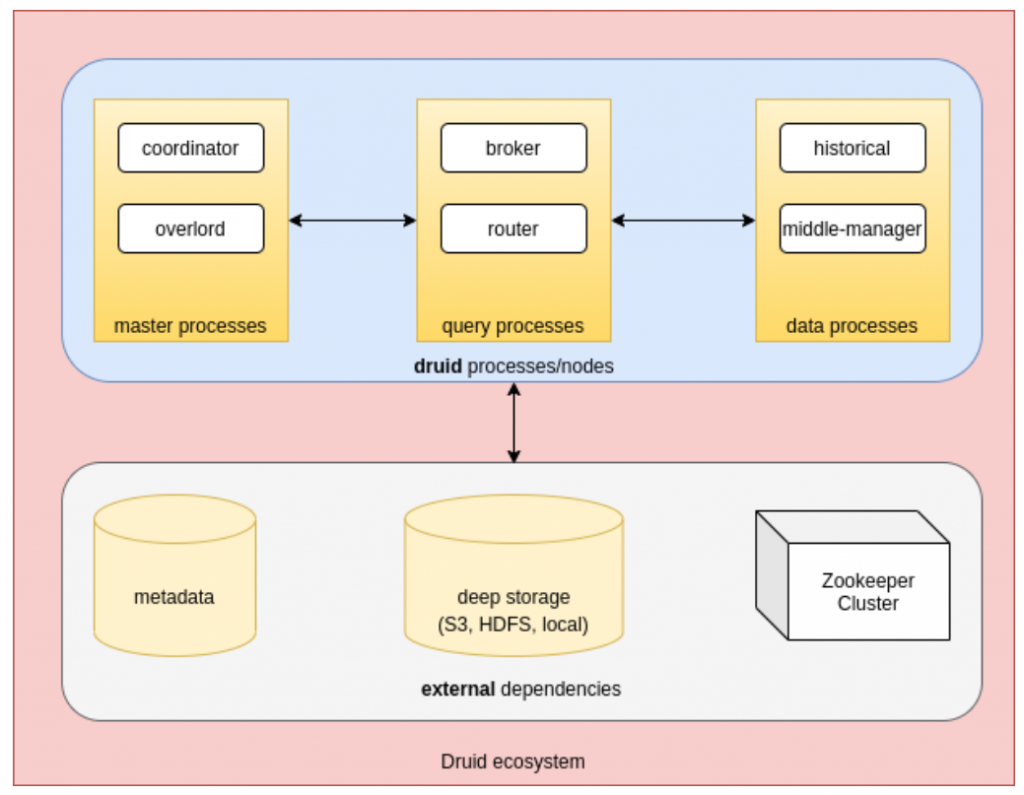
On notera le terme « process » qui est utilisé à plusieurs reprises sur le schéma, repris de la documentation officielle. Cela veut dire que les composants Druid peuvent être déployés de manière colocalisé ou indépendante. La suite de l’article utilisera le terme process pour éviter la confusion.
Nous allons ensuite expliquer les différentes processes, cela peut être flou au départ au vu des termes utilisés, mais au fur et à mesure de la lecture, cela sera de plus en plus clair.
Master
Coordinator
Le but du coordinator est de faire en sorte que les segments de données soient bien distribués correctement entre les Historical Processes, c’est-à-dire l’allocation des données initiale, la suppression, le transfert depuis le Deep Storage, la Replication ainsi que le Balancing. Cela se fait en se basant sur trois types de règles : Load Rules, Drop Rules et le Broadcast Rules.
Overlord
L’overlord, bien que ce nom soit badass, il s’agit en fait du gestionnaire de tâches (Task Manager). Les tâches sont les unités de travail dans Apache Druid qui couvre des opérations comme le commencement et la coordination de l’ingestion de la donnée.
Query
Broker
Les brokers sont le premier point de contact pour les requêtes, ils font en sorte de découvrir où se trouve la donnée et de les compiler à partir des différentes sources où elle réside afin de les fournir au client demandeur. Un router est une fonctionnalité expérimentale qui agit en tant que proxy pour les autres processes.
Data
Historical processes
Les Historical processes conservent les données interrogeables.
Middle-Manager
Le Middle-Manager prend soin d’ingérer la donnée (dans ce cas, on dit également indexer), mais il participe également à fournir la donnée aux brokers si l’ingestion de la donnée se fait par le biais d’une tâche de type streaming/temps réel comme Kafka.
Comment la donnée est envoyée dans l’architecture Druid ?
Principe de persistance de la donnée
La data ingestion
La première chose à savoir est que Druid est celui qui récupère la donnée en effectuant des tâches d’indexation. Il existe deux types de tâches d’indexation :
- Tâches d’ingestion Streaming / Temps réel
- Donnée directe et continue comme avec Apache Kafka ou AWS Kinesis par exemple
- Seulement pour ajouter de la nouvelle donnée
- Tâches d’ingestion Batch
- Opérations d’ingestion en one shot à partir de sources comme Amazon S3, Google Cloud Storage, HDFS, fichiers en local
- Peut être également utilisé pour écraser la donnée existante (overwrite)
- Tâches d’ingestion Streaming / Temps réel
La donnée qui est importée via les tâches atterrit dans ce qu’on appelle des Datasources, ce sont des éléments analogues aux tables des bases de données traditionnelles. La donnée des Datasources est partitionée en Segments. C’est un set de données groupées par temps. En coulisse, un Segment est un fichier au format colonne où l’index est, par défaut, le timestamp.

Les Dimensions représentent la donnée, et les Metrics sont les informations agrégées dérivées de la donnée.
Le diagramme ci-dessous illustre le cheminement de la donnée, commençant par la source d’entrée jusqu’au Historical Process, le process responsable de répondre aux requêtes.
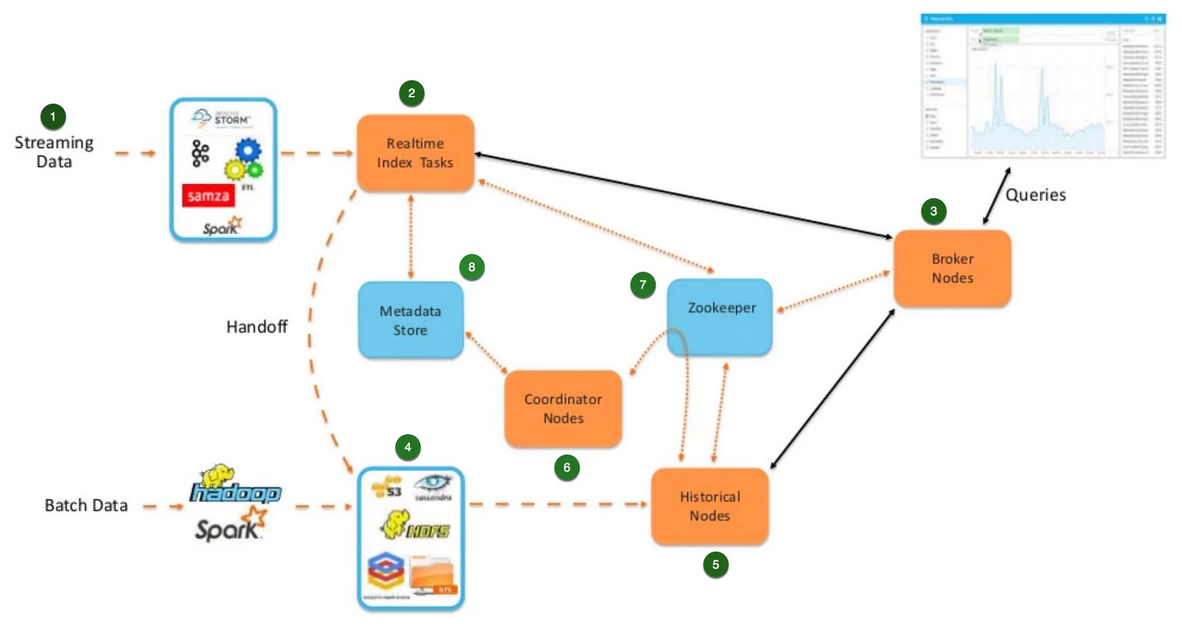
Le diagramme peut être intimidant à première vue, voici ce qui se passe :
- Des données arrivent en continu depuis n’importe quelle source. Elles peuvent être préalablement transformées et enrichies.
- Une fois que le traitement est terminé, la donnée est envoyée dans la tâche d’indexation temps réel. La tâche conserve la donnée en mode ligne de mémoire et s’il y a une requête qui arrive entre temps, la donnée pourra être interrogée depuis ces nœuds temps réel.
- La requête touchera d’abord le Broker Node. Ce Broker Node verra qu’il a de la donnée dans la tâche d’indexation temps réel et il enverra la requête vers la tâche. En réponse, la tâche d’indexation temps réel renverra le résultat au Broker Node et l’évènement sera visible sur le tableau de bord.
- Si la donnée est restée dans les tâches d’indexation depuis un moment, les tâches vont créer un format orienté colonne, aussi appelé un Segment Druid. Ces segments seront transférés vers le Deep Storage. (Note : le Deep Storage peut être n’importe quel système de fichiers distribués, il peut être utilisé comme un moyen de backup permanent des Segments de données).
- Une fois la donnée présente dans le Deep Storage, elle est ensuite chargée dans les Historical Nodes. Ensuite les tâches d’indexation vont voir les Segments chargés dans les Historical Nodes, ils vont ainsi libérer les Segments qui sont stockés dans leur mémoire. Donc si une requête arrive, les données proviendront des Historical Nodes.
- L’architecture Druid exploite les Coordinator Nodes pour gérer où les segments ont besoin d’être chargés. Ils sont responsables de coordonner la donnée à travers les différents Historical Nodes. Les Coordinators Nodes sont également responsables de la gestion de la réplication de la donnée. Il est possible de configurer des règles de chargement de données. Par exemple, on peut établir une règle qui veille à ce que l’équivalent d’un mois de données soit chargé dans les Historical Nodes avec les Coordinator Nodes.
- Zookeeper est utilisé pour la communication en interne avec les composants. Il permet également les failovers.
- Il y a une dépendance externe sur le Metadata Store. Ça peut être une base de données MySQL ou Postgres. Il permet de stocker la métadonnée des Segments Druid, c’est-à-dire la taille des segments, leur localisation dans le Deep Storage ainsi que le schéma de la donnée.
- L’overload remet la tâche d’indexation au Middle-Manager. Ce dernier prend soin de récupérer la donnée à partir de sa source, composant ainsi des Segments de données.
- La donnée segmentée est persistée dans le Deep Storage, ensuite une entrée correspondante est créée dans le Metadata Store. Cette entrée garde une trace de la taille des segments, leur localisation dans le Deep Storage ainsi que le schéma de la donnée.
- Le coordinator interroge périodiquement le Metadata Store pour voir quelles données ne sont pas encore disponibles et les copie dans le Deep Storage vers un ou plusieurs Historical Processes.
- Dans le cas où la donnée vient d’une tâche Streaming, après avoir été segmentée, elle sera déjà interrogeable pendant un court laps de temps, jusqu’à qu’elle soit également copiée dans un Historical Process.
Ré-indexation de la donnée
Comme mentionné un peu plus tôt, les tâches d’indexation batch sont les seules qui peuvent être utilisées pour écraser la donnée déjà ingérée. Ceci peut être effectué pour de la donnée initialement ingérée par le même type de tâche d’indexation, ou par des tâches d’indexation streaming. Les tâches d’indexation Streaming, cependant, ne peuvent pas être utilisées pour écraser de la donnée.
Suppression de la donnée
Pour compléter le cycle de la donnée, nous allons rapidement mentionner que supprimer de la donnée depuis une Datasource implique deux étapes :
- Marquer la donnée en tant que « unused » (non utilisée)
- Créer une tâche « kill » (Tuer !) qui cherche de la donnée marquée comme non utilisée, puis la supprime définitivement, même dans le Deep Storage
La fréquence ou la quantité de donnée à supprimer est configurable via le Drop Rules du coordinator.
Interrogation de la donnée
Comme mentionné précédemment, la donnée pouvant être interrogée provient de tâches d’indexation Streaming, ou des Historical processes. Les requêtes proviennent des Brokers, qui identifie quels Historical/Middle-Manager processes possèdent les segments cibles et fusionne ces segments.
Une des raisons pour laquelle l’architecture Druid permet de hautes performances, est la suivante : avant de lire quoi que ce soit, les requêtes passent par trois processes filtre :
- Identification des segments nécessaires ainsi que leur localisation pour être récupérés
- Dans chaque segment, utilisation des indexes pour identifier quels lignes doivent être accédées
- Dans chaque ligne, accès seulement aux colonnes pertinentes aux requêtes
Et maintenant, à quoi ressemble ces requêtes ?
Druid fournit deux méthodes pour interroger la donnée :
- Druid SQL
- Requêtes basées sur JSON
Druid SQL
Druid SQL est la partie SQL intégrée de Druid, elle est basée sur Apache Calcite.
Il n’est pas nécessaire d’apprendre un nouveau langage pour interroger la donnée sur Druid. Ça veut dire, par exemple, que les requêtes SELECT supportent les mots-clés FROM, WHERE, GROUP BY, HAVING, ORDER BY, LIMIT, UNION ALL, EXPLAIN PLAN, ainsi que les sous-requêtes.
Dans la documentation de Druid, un dataset Wikipédia est souvent utilisé pour illustrer les exemples, voici à quoi ressemble une requête SQL :
SELECT “page”, COUNT(*) as “count” FROM “wikipedia” GROUP BY 1 ORDER BY “count” DESC
Ici, “wikipedia” se réfère à la DataSource et “page” à la colonne de la DataSource.
Pour effectuer des requêtes plus complexes, les fonctions sont également supportées, comme les fonctions scalaires (ABS, CONCAT, CURRENT_TIMESTAMP, etc…) ainsi que les fonctions d’agrégation (SUM, MIN/MAX, etc…).





